开发专题
队列
RabbitMQ消息队列
redis+mq实现秒杀功能
非结构化存储OSS
使用minio进行数据存储
非结构化文档在线预览
使用kkfileView实现在线文档预览
OnlyOffice实现文档在线编辑
全文搜索
Elasticsearch构建全文搜索系统
windowns下使用Logstash7.6.2同步Mysql数据到ElasticSearch,并使用kibana进行检索
工作流Flowable应用
Flowable基础入门知识
Springboot+mybatisplus+flowable6.5.0 开发房产审批模块
人脸识别
虹软人脸识别应用
人脸识别基础入门知识
WebSocket在线聊天
Springboot+WebSocket+redis实现在线客服系统
WebSocket基础入门
信创产业
领域驱动DDD
定时任务quartz
流媒体
流媒体服务LALMAX的部署安装与使用
使用go2rtc+webrtc-streamer在网页上播放rtsp 的摄像头视频
RPA数字员工
使用盘匠设计器进行RPA项目的开发
RPA开发过程中的一些经验之谈
业务系统
litemall开源商城
dbblog开源博客
electron-egg关于通信部分的一些补充
本文档使用 MrDoc 发布
-
+
首页
windowns下使用Logstash7.6.2同步Mysql数据到ElasticSearch,并使用kibana进行检索
### 背景: > 手上有一个现成的数据表,数据量比较大,2000万条,存放在mysql数据库 > > 检索的速度比较慢,现在想把这个数据存入es,实现快速检索 ### 准备 1. 已经安装好的es7.6.2版本 2. 下载好的mysql-connector-java驱动,我这里使用的是 mysql-connector-java-8.0.30.jar 3. mysql待索引的数据库 4. 已经安装好的kibana并且已经和es配置的对接。 5. logstash7.6.2的程序包 ### 下载 ElasticSearch、logstash7.6.2、kibana 三个软件的全平台版本推荐到下面这个网站直接点击下载: https://elasticsearch.cn/download/ 我这里选择下载logstash7.6.2的windows版本,然后解压 到本地。 解压之后进入bin目录,新建一个 mysql.conf文件,内容如下: > jdbc_connection_string、jdbc_driver_library、statement、elasticsearch.host elasticsearch.index 都根据实际情况修改成自己的。jdbc_page_size 是一个分页数,logstash会分页去检索数据,前提是开启了jdbc_paging_enabled。。 ~~~json input { stdin{ } jdbc { # 连接的数据库地址和数据库,指定编码格式,禁用SSL协议,设定自动重连 jdbc_connection_string => "jdbc:mysql://10.168.1.184:3306/db_2000?characterEncoding=UTF-8&useSSL=false&autoReconnect=true" # 用户名密码 jdbc_user => "root" jdbc_password => "123456" # jar包的位置 jdbc_driver_library => "C:\_software2\logstash-7.6.2\mysql\8.0.30\mysql-connector-java-8.0.30.jar" # mysql的Driver jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_default_timezone => "Asia/Shanghai" jdbc_paging_enabled => "true" jdbc_page_size => "50" # statement_filepath => "config-mysql/test.sql" # 注意这个sql不能出现type,这是es的保留字段 statement => "select id,`name`,birthday,gender,address,mobile,nation from tb_kaifang limit 1000 " # schedule => "* * * * *" } } output { elasticsearch { hosts => "10.168.1.216:9200" # index名 index => "kaifang" # type名 document_type => "_doc" # 需要关联的数据库中有有一个id字段,对应索引的id号 document_id => "%{id}" } stdout { codec => json_lines } } ~~~ 部分参数配置说明: ~~~ jdbc_driver_library: jdbc驱动的路径,在上一步中已经下载 jdbc_driver_class: 驱动类的名字,mysql填com.mysql.jdbc.Driver jdbc_connection_string: mysql 地址 jdbc_user: mysql 用户 jdbc_password: mysql密码 schedule: 执行sql时机,类似 crontab 的调度,上面配置表示每分钟刷新一次。 statement: 要执行的sql,以 “:” 开头是定义的变量,可以通过parameters 来设置变量,这里的sql_last_value是内置的变量,表示上一次sql执行中> -> update_time的值 statement_filepath:和上面statement参数二选一,存放需要执行的SQL语句的文件位置,适用于多个sql语句的场景。 use_column_value: 使用递增列的值 tracking_column_type: 递增字段的类型,numeric表示数值类型, timestamp 表示时间戳类型 tracking_column: 递增字段的名称,这里使用updatetime这一列,这列的类型是timestamp last_run_metadata_path: 同步点文件,这个文件记录了上次的同步点,重启时会读取这个文件,这个文件可以手动修改 index: 导入到es中的index名,这里我直接设置成了mysql表的名字 document_id: 导入到es中的文档id,这个需要设置成主键,否则同一条记录更新后在es中会出现两条记录,%{id} 表示引用mysql表中id字段的值 ~~~ 我这里从tb_kaifang这个表里选取了 7个字段:id,`name`,birthday,gender,address,mobile,nation 请在es里同时新建一个一一对应的索引库。 脚本如下,我这里选择直接通过在kibana的Dev Tools图形化界面手动执行。  ~~~js PUT /kaifang { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings":{ "properties":{ "id":{ "type":"integer" }, "name":{ "type":"keyword" }, "birthday":{ "type":"keyword" }, "gender":{ "type": "keyword" }, "address":{ "type":"text", "analyzer": "ik_smart", "search_analyzer": "ik_smart" }, "mobile":{ "type": "keyword" }, "nation":{ "type": "keyword" } } } } ~~~ 查看刚刚新建的索引 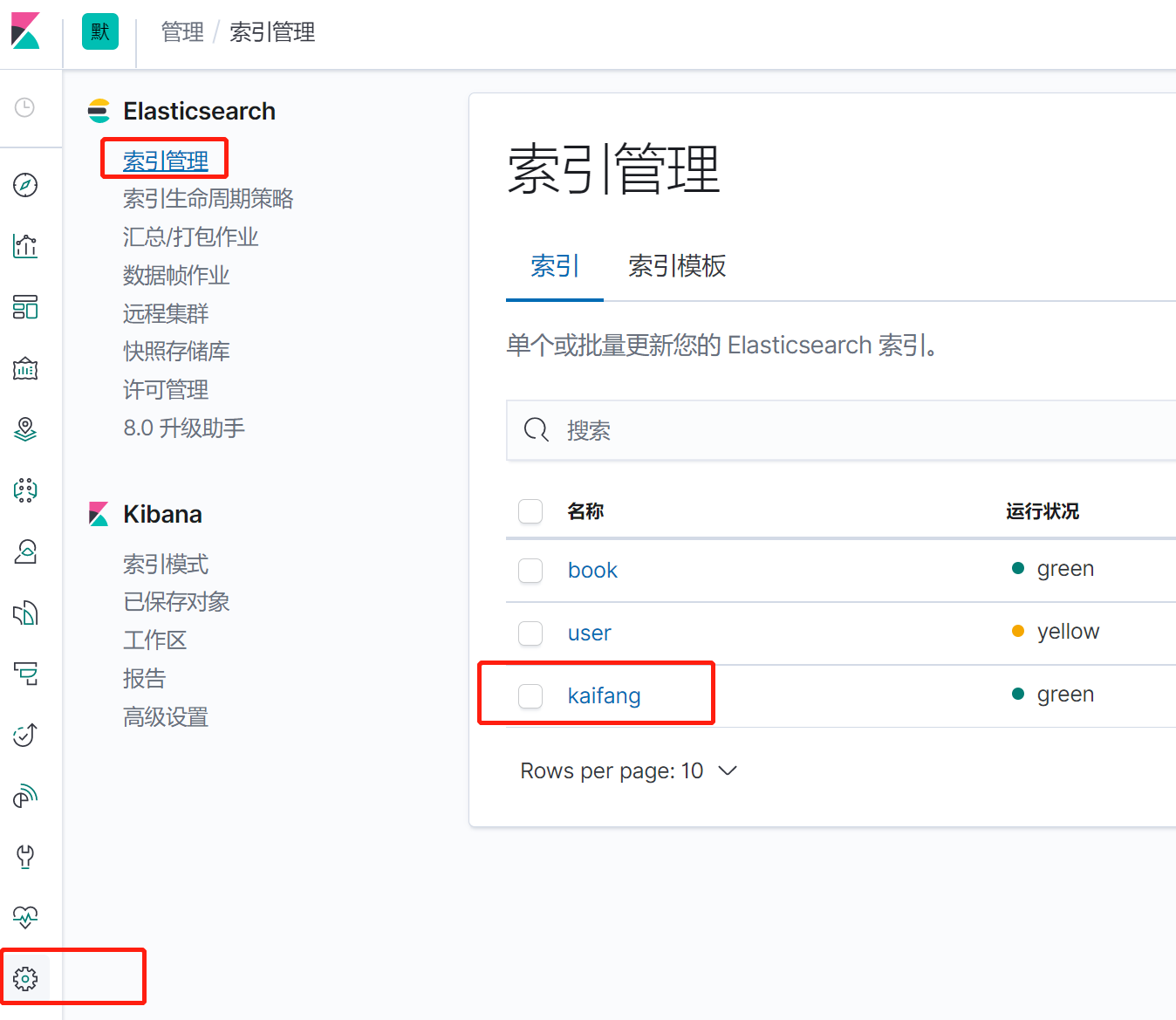 ### 抽取mysql数据并推送到es 进入logstash7.6.2的bin目录,我这里是windows环境,打开powershell 执行 ~~~ .\logstash -f mysql.conf ~~~ ### 在kibana中查看索引数据 #### 预设索引 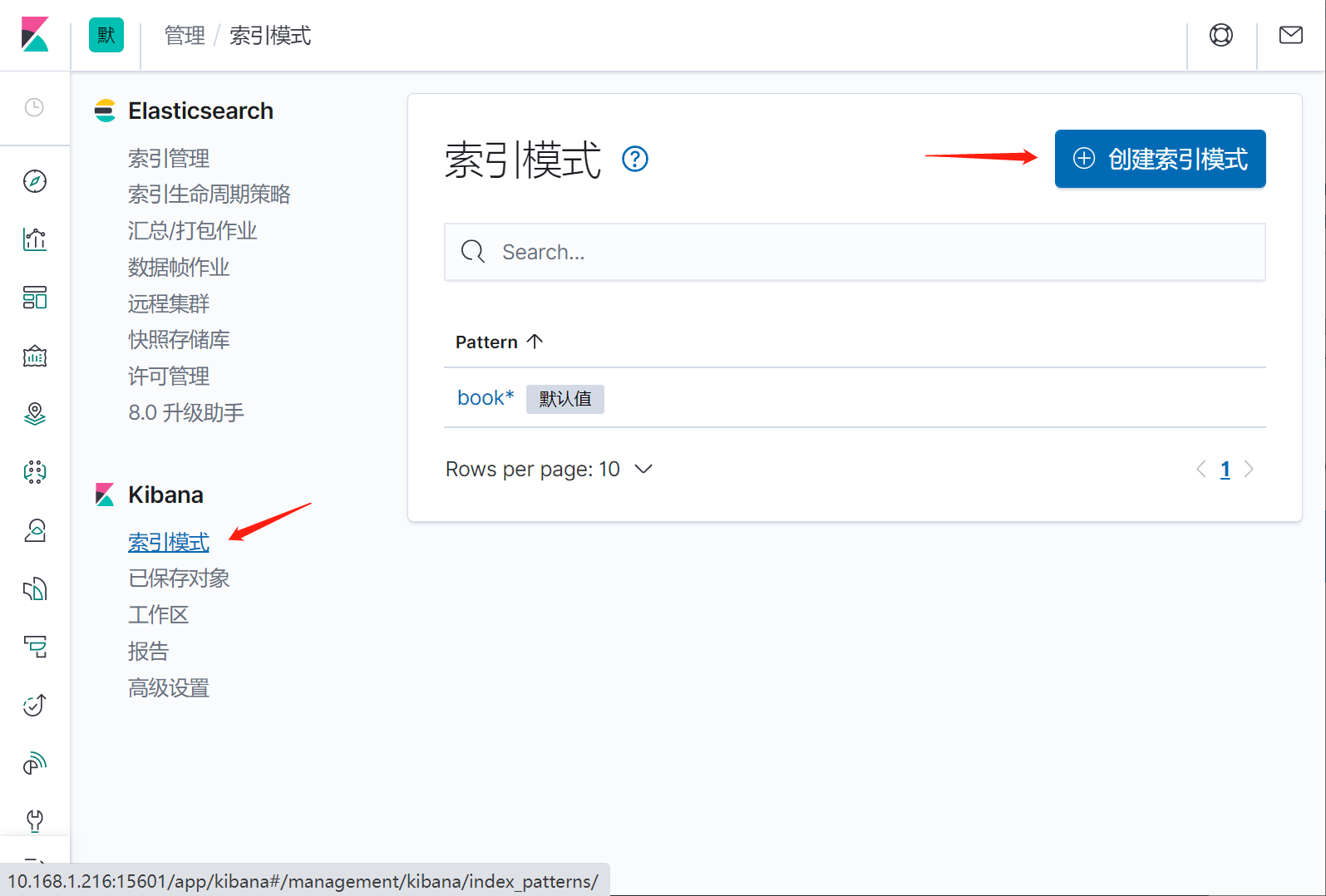 #### 输入kaifang*,然后下一步 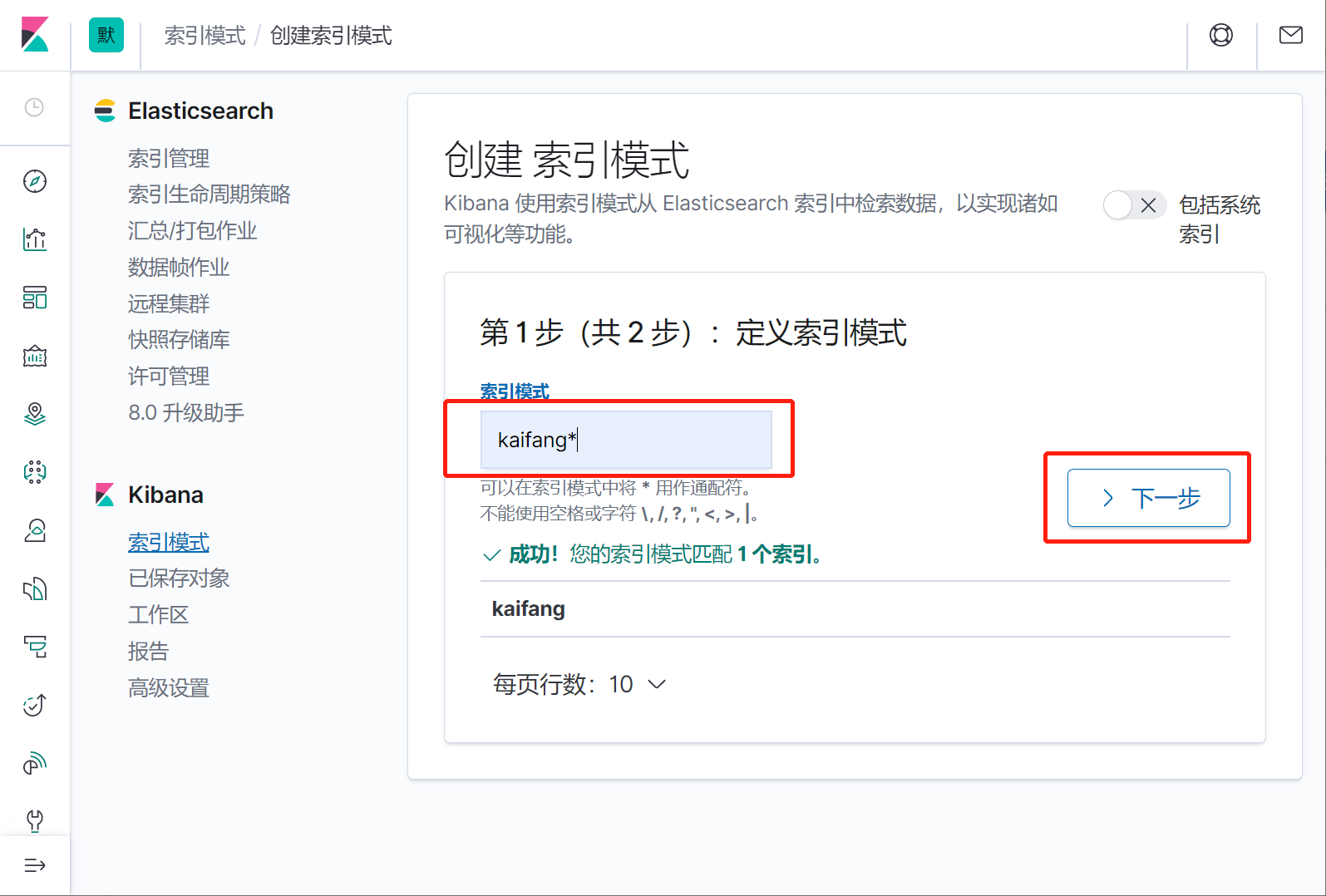 #### 等待完成 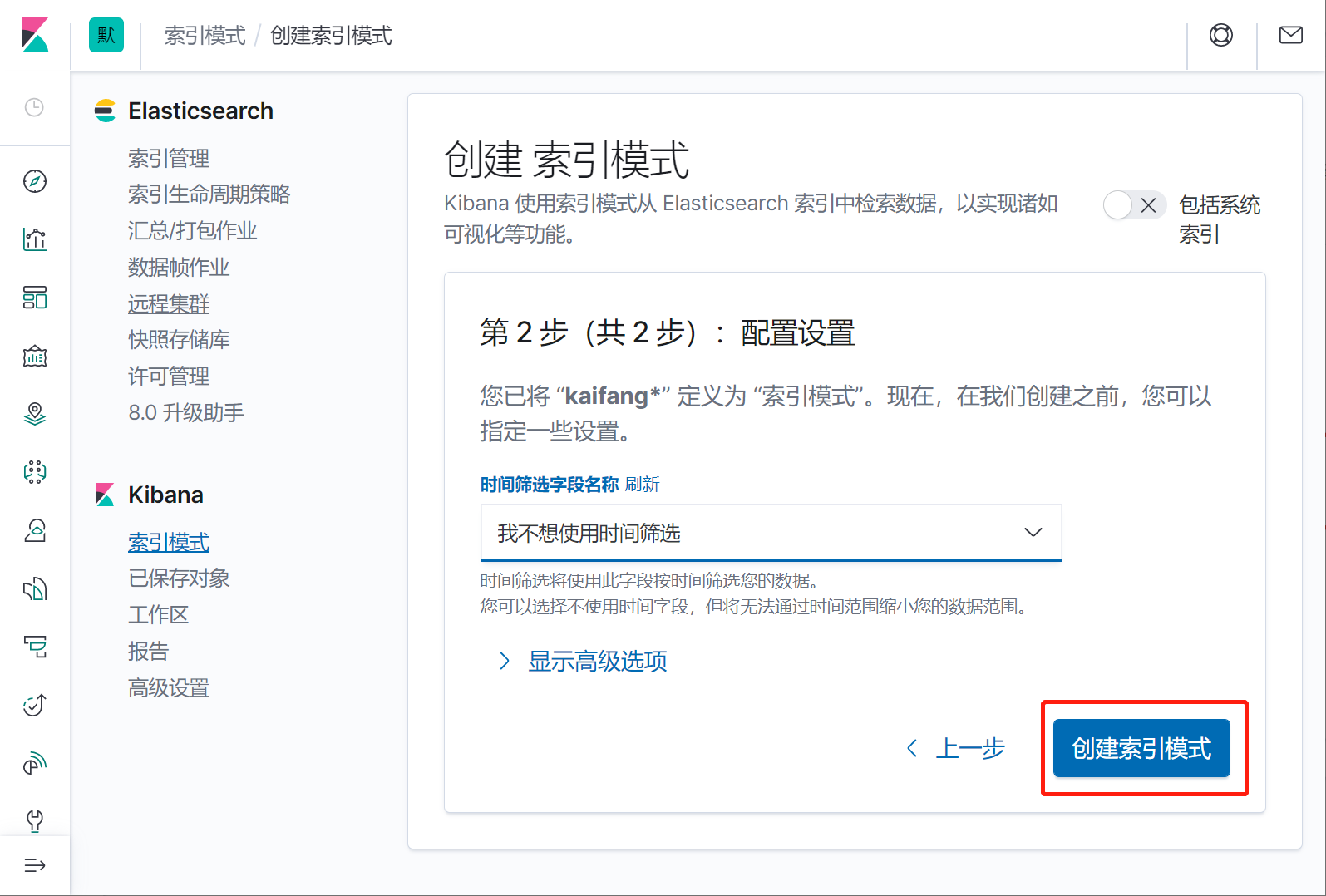 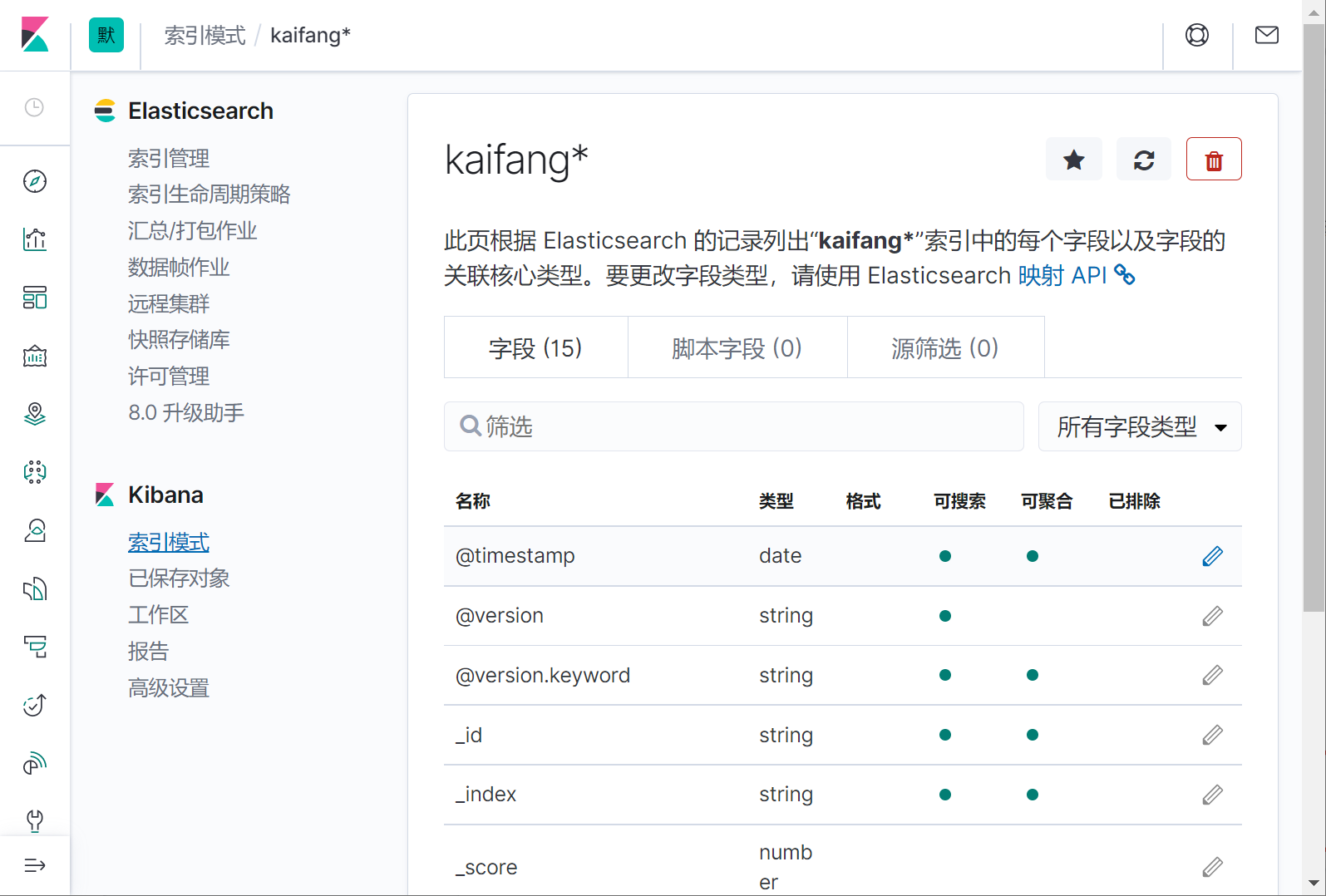 #### 回到控制台进行快乐的检索吧 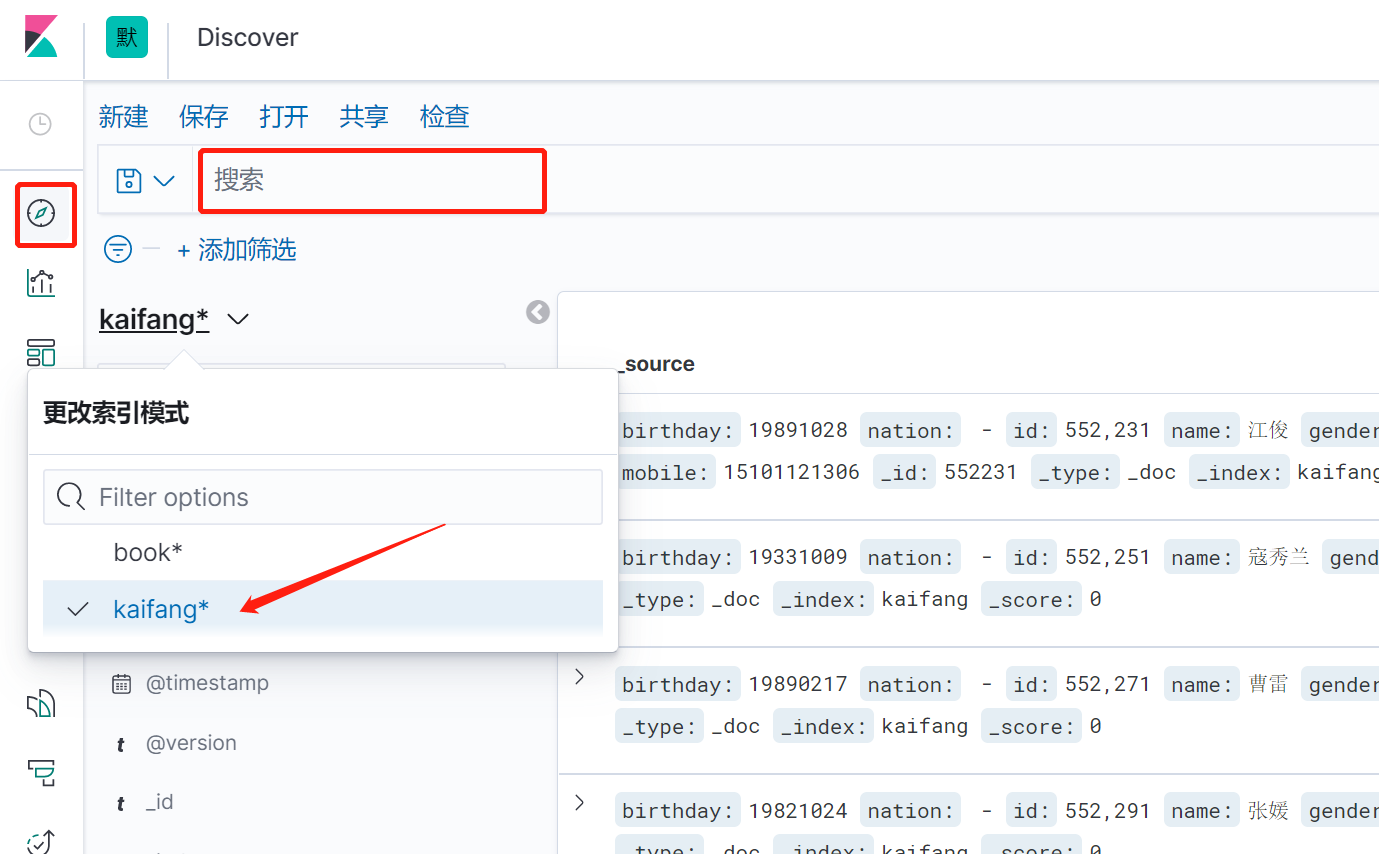 ### 后话 logstash在这里只是演示了简单的把mysql的数据推到es里,只是logstash的很小的一个功能点 在实际应用场景中,还可以 配置调度周期,增加filter过滤器,拉取日志并写入mysql,从mysql抽取,然后加工处理后,再回写入mysql ,完全就是一个强大的etl数据抽取神器啊。。
superadmin
2023年10月5日 00:13
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码